Knowledge graphs have been proven extremely useful in powering diverse applications in semantic search and natural language understanding. In this work, we present GraphGen4Code, a toolkit to build code knowledge graphs that can similarly power various applications such as program search, code understanding, bug detection, and code automation. GraphGen4Code uses generic techniques to capture code semantics with the key nodes in the graph representing classes, functions and methods. Edges indicate function usage (e.g., how data flows through function calls, as derived from program analysis of real code), and documentation about functions (e.g., code documentation, usage documentation, or forum discussions such as StackOverflow). Our toolkit uses named graphs in RDF to model graphs per program, or can output graphs as JSON. We show the scalability of the toolkit by applying it to 1.3 million Python files drawn from GitHub, 2,300 Python modules, and 47 million forum posts. This results in an integrated code graph with over 2 billion triples. We make the toolkit to build such graphs as well as the sample extraction of the 2 billion triples graph publicly available to the community for use.
- Paper: https://arxiv.org/abs/2002.09440
- Download GraphGen4Code dataset as nquads from here.
Table of Contents
- How is GraphGen4Code different from other frameworks?
- Sample Graphs Generated by GraphGen4Code
- Applications
- Sample Schema
- Create your own graph
- Example Queries
- Publications
How is GraphGen4Code different from other frameworks?
Static analysis in GraphGen4Code is different from other analysis libraries in that it:
- Does not assume each program is self contained, but in fact uses other libraries. Calls to each library function is explicitly modeled in the analysis (and data flow is approximated through the call).
- Follows data and control flow across multiple function calls within the same script.
- Simulates each function call within the script, even if the script does not explicitly call the functions (i.e., there is no main). This sort of analysis is needed to handle real Python code - most are full of library calls, most have different functions through which data flow and control flow occurs. Many of the real world applications we look at that have been built on top of GraphGen4Code require for instance starting points for analysis that are library calls (e.g., start with pandas.read_csv), and proceeds till some end condition is needed (e.g., end with a fit call on any of the estimators in a data science pipeline).
Indeed, this is a better approximation of program graphs than what is currently produced by frameworks such as python_graphs. When using python_graphs as an example, that framework assumes:
- Every function call occurs within the scope of the program. No library calls appear in the program graph.
- The analysis is strictly NOT interprocedural.
- Only calls within a script to a function are modeled.
Sample Graphs Generated by GraphGen4Code
1.3 Million Python Programs from Github
To demonstrate GraphGen4Code’s scalability, we build graphs for 1.3 million Python programs (where program refers to a single Python script) on GitHub, each analyzed into its own separate graph. We also use the toolkit to link library calls to documentation and forum discussions, by identifying the most commonly used modules in code, and trying to connect their classes, methods or functions to relevant documentation or posts. For forum posts, we used information retrieval techniques to connect it to its relevant methods or classes. We performed this linking for 257K classes, 5.8M methods, and 278K functions, and processed 47M posts from StackOverflow and StackExchange. This shows the feasibility of using the Graph4CodeGen toolkit for building large-scale knowledge graphs for code that captures code semantics as well as natural language artifcacts about code.
All graph files are available here.
To load and query this data, please follow the instructions here. We also provide scripts for creating a docker image with the graph database ready to use.
ETH 150k Python Dataset
We also used GraphGen4Code to produce graphs for ETH 150k Python Dataset collected from Github. ETH-150K dataset has been used to train models for code recommendation, type inferencing, program repairs, …etc. We provide graph data for this dataset in both JSON and RDF N-Quads formats.
Schema
The following shows a code snippet example as well as a high level overview of the information generated by GraphGen4Code from code analysis, StackOverflow, and docstrings. We provide a random sample of each data source in RDF format here.
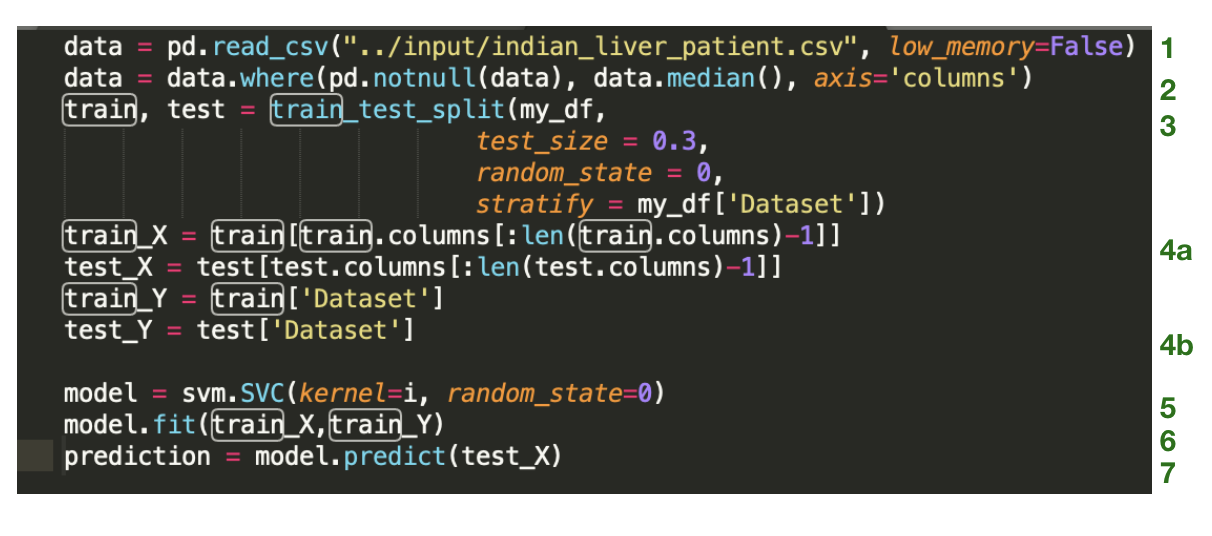
Code Snippet Example
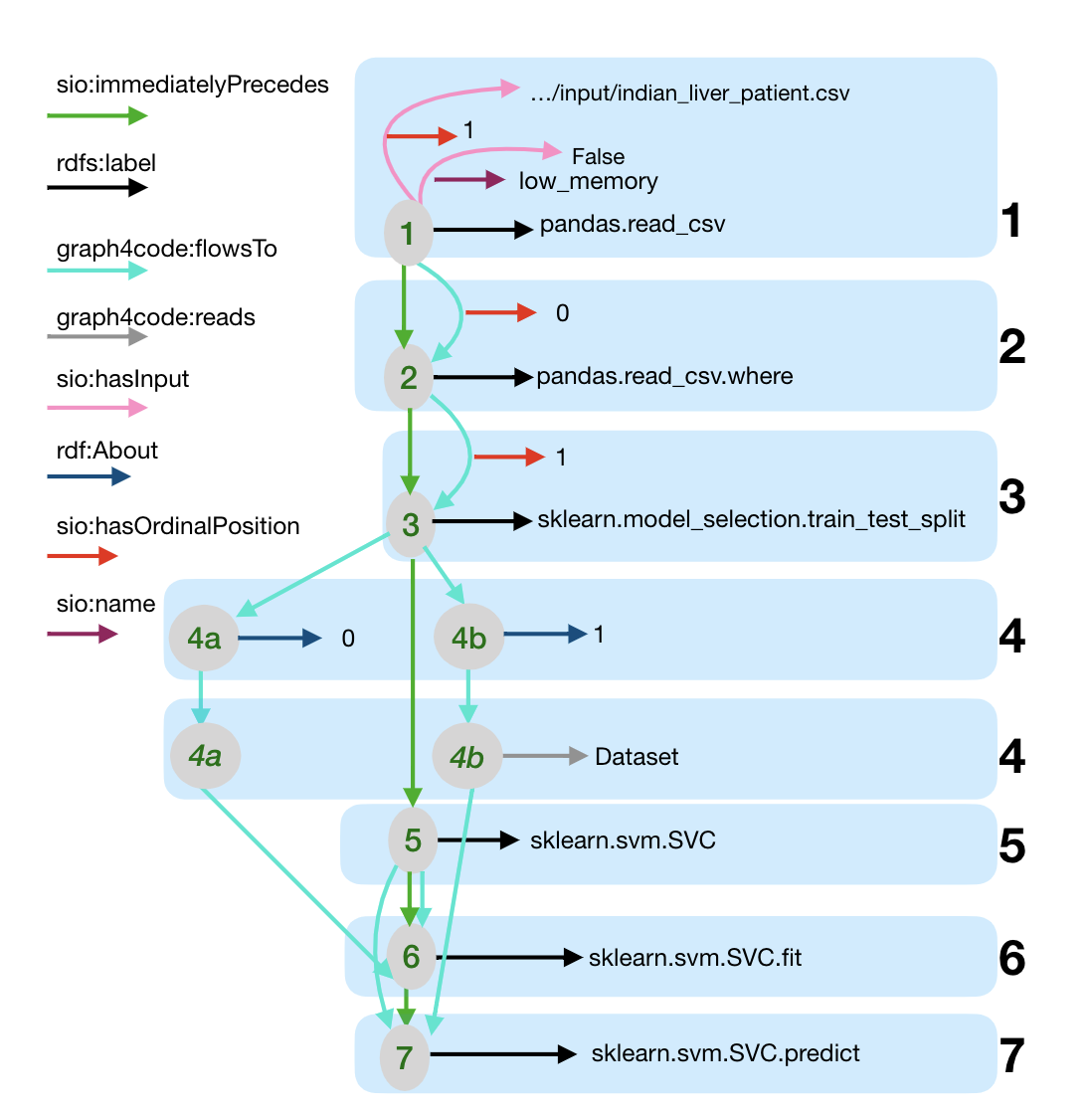
Dataflow graph for the running example
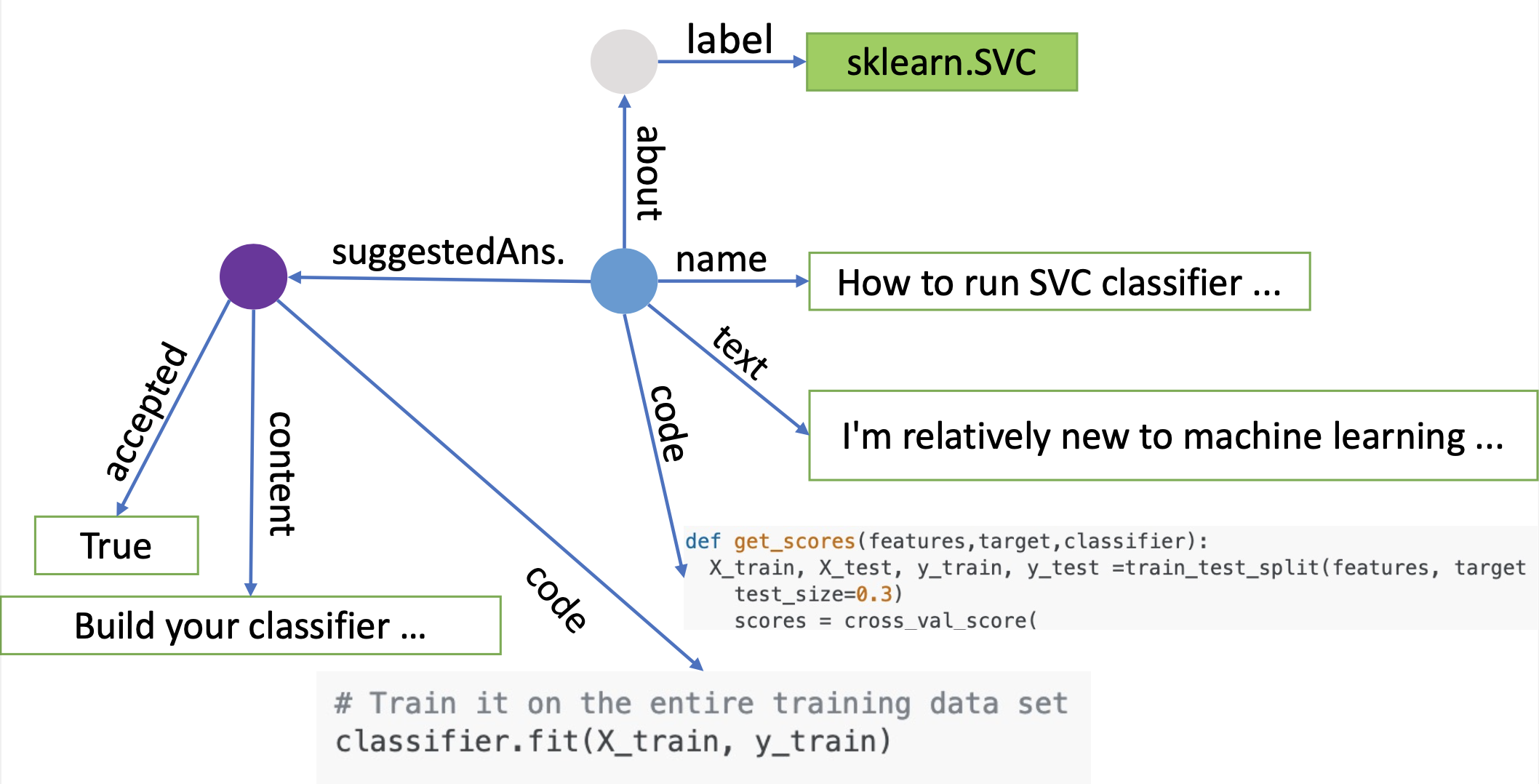
StackOverflow Graph Example
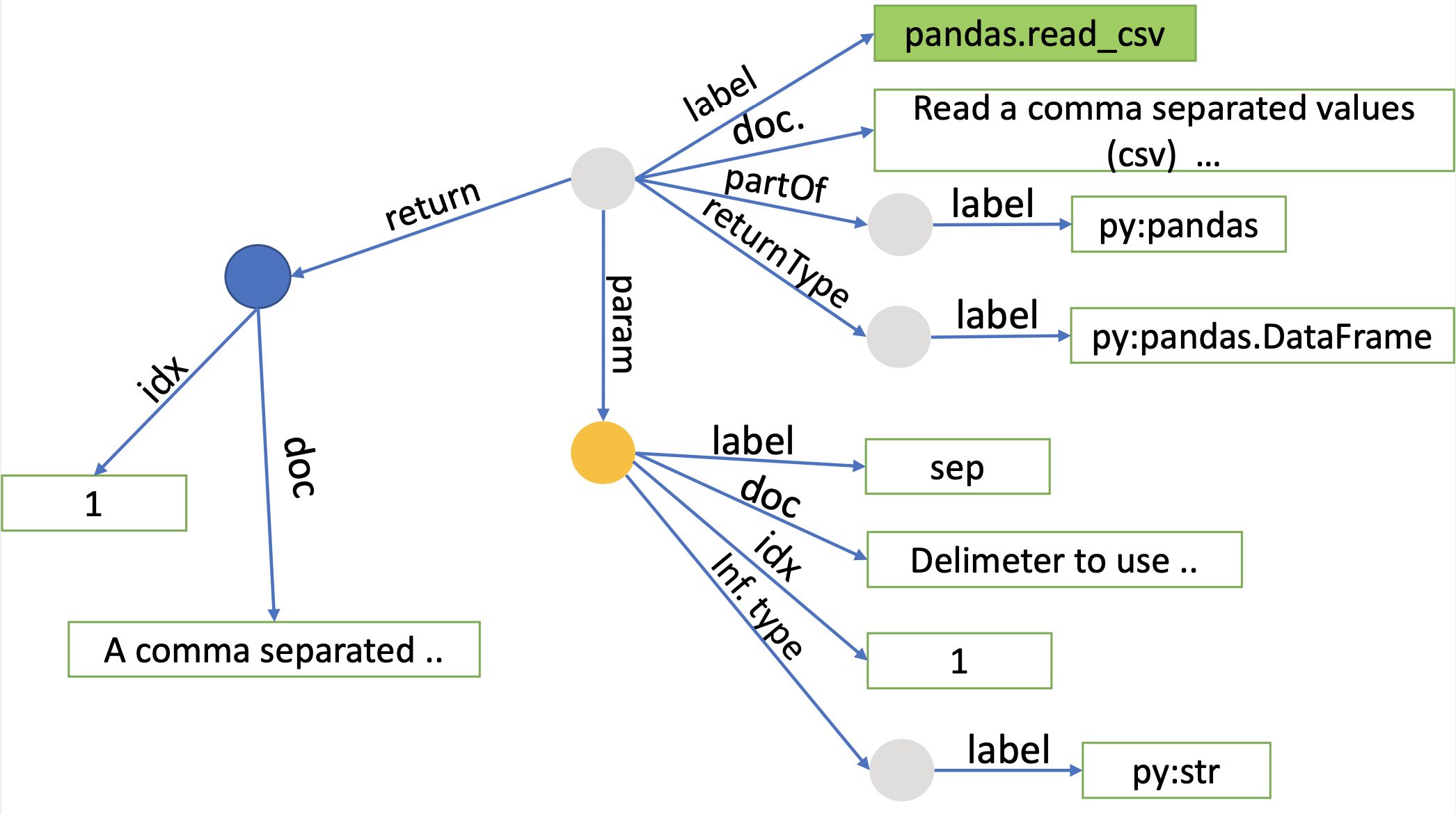
Docstrings Graph Example
Publications
- If you use GraphGen4Code in your research, please cite our work:
@inproceedings{abdelaziz2023semforms,
title={ SemFORMS: Automatic Generation of Semantic Transforms By Mining Data Science Code },
author={Ibrahim Abdelaziz, Julian Dolby, Udayan Khurana, Horst Samulowitz, Kavitha Srinivas,
booktitle={The 32nd International Joint Conference on Artificial Intelligence (IJCAI-23) (demo)},
year={2023}
}
@inproceedings{helali2022,
title={A Scalable AutoML Approach Based on Graph Neural Networks},
author={Mossad Helali and Essam Mansour and Ibrahim Abdelaziz and Julian Dolby and Kavitha Srinivas},
booktitle={Proceedings of the Very Large Data bases (VLDB 2022)},
year={2022}
}
@inproceedings{abdelaziz2022blanca,
title={Can Machines Read Coding Manuals Yet? -- A Benchmark for Building Better Language Models for Code Understanding},
author={Ibrahim Abdelaziz and Julian Dolby and Jamie McCusker and Kavitha Srinivas},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence (AAAI 2022)},
year={2022}
}
@article{abdelaziz2021graph4code,
title={A Toolkit for Generating Code Knowledge Graphs},
author={Abdelaziz, Ibrahim and Dolby, Julian and McCusker, James P and Srinivas, Kavitha},
journal={The Eleventh International Conference on Knowledge Capture (K-CAP)},
year={2021}
}
@article{abdelaziz2020codebreaker,
title={A Demonstration of CodeBreaker: A Machine Interpretable Knowledge Graph for Code},
author={Abdelaziz, Ibrahim and Srinivas, Kavitha and Dolby, Julian and McCusker, James P},
journal={International Semantic Web Conference (ISWC) (Demonstration Track)},
year={2020}
}