Applications
Automated Machine Learning
AutoML systems build machine learning models automatically by performing a search over valid data transformations and learners, along with hyper-parameter optimization for each learner. We present a system called KGpip, based on GraphGen4Code analysis, for the selection of transformations and learners, which (1) builds a database of datasets and corresponding historically used pipelines using effective static analysis instead of the typical use of actual runtime information, (2) uses dataset embeddings to find similar datasets in the database based on its content instead of metadata-based features, (3) models AutoML pipeline creation as a graph generation problem, to succinctly characterize the diverse pipelines seen for a single dataset. KGpip is designed as a sub-component for AutoML systems. We demonstrate this ability via integrating KGpip with two AutoML systems and show that it does significantly enhance the performance of existing state-of-the-art systems.
Paper: https://arxiv.org/abs/2111.00083
Code: https://github.com/CoDS-GCS/kgpip-public
We also use this analysis for feature engineering from code. Within an enterprise, several data scientists often work with the same type of data. SEMFORMS and DataRinse help data scientists leverage existing code for either feature engineering (SEMFORMS) or for cleansing data (DataRinse).
SEMFORMS Paper: https://arxiv.org/abs/2111.00083
DataRinse Paper: https://dl.acm.org/doi/10.14778/3611540.3611628
Buildng Better Language Models for Code Understanding
Code understanding is an increasingly important application of Artificial Intelligence. A fundamental aspect of understanding code is understanding text about code, e.g., documentation and forum discussions. Pre-trained language models (e.g., BERT) are a popular approach for various NLP tasks, and there are now a variety of benchmarks, such as GLUE, to help improve the development of such models for natural language understanding. However, little is known about how well such models work on textual artifacts about code, and we are unaware of any systematic set of downstream tasks for such an evaluation. In this paper, we derive a set of benchmarks (BLANCA - Benchmarks for LANguage models on Coding Artifacts) that assess code understanding based on tasks such as predicting the best answer to a question in a forum post, finding related forum posts, or predicting classes related in a hierarchy from class documentation. We evaluate the performance of current state-of-the-art language models on these tasks and show that there is a significant improvement on each task from fine tuning. We also show that multi-task training over BLANCA tasks helps build better language models for code understanding.
Paper: https://arxiv.org/abs/2109.07452
Code: https://github.com/wala/blanca
Large Scale Generation of Labeled Type Data for Python
Recently, dynamically typed languages, such as Python, have gained unprecedented popularity. Although these languages alleviate the need for mandatory type annotations, types still play a critical role in program understanding and preventing runtime errors. An attractive option is to infer types automatically to get static guarantees without writing types. Existing inference techniques rely mostly on static typing tools such as PyType for direct type inference; more recently, neural type inference has been proposed. However, neural type inference is data hungry, and depends on collecting labeled data based on static typing. Such tools, however, are poor at inferring user defined types. Furthermore, type annotation by developers in these languages is quite sparse. In this work, we propose novel techniques for generating high quality types using 1) information retrieval techniques that work on well documented libraries to extract types and 2) usage patterns by analyzing a large repository of programs. Our results show that these techniques are more precise and address the weaknesses of static tools, and can be useful for generating a large labeled dataset for type inference by machine learning methods. F1 scores are 0.52-0.58 for our techniques, compared to static typing tools which are at 0.06, and we use them to generate over 37,000 types for over 700 modules.
Dataset: https://github.com/wala/graph4code/tree/master/type_inference_results
Paper: coming soon
Recommendation engine for developers
CodeBreaker is a coding assistant built on top of Graph4Code to help data scientists write code. The coding assistant helps users find the most plausible next coding step, finds relevant stack overflow posts based purely on the users’ code, and allows users to see what sorts of models other people have constructed for data flows similar to their own. CodeBreaker uses the Language Server Protocol (LSP) to provide integration with any IDE. For a detailed description of this use case, see the demo paper. A video of this use case is also here.
Paper: http://ceur-ws.org/Vol-2721/paper568.pdf
Enforcing best practices
Many best practices for API frameworks can be encoded into query templates over data flow and control flow. Here we give three such examples for data science code, along with queries which can be templatized.
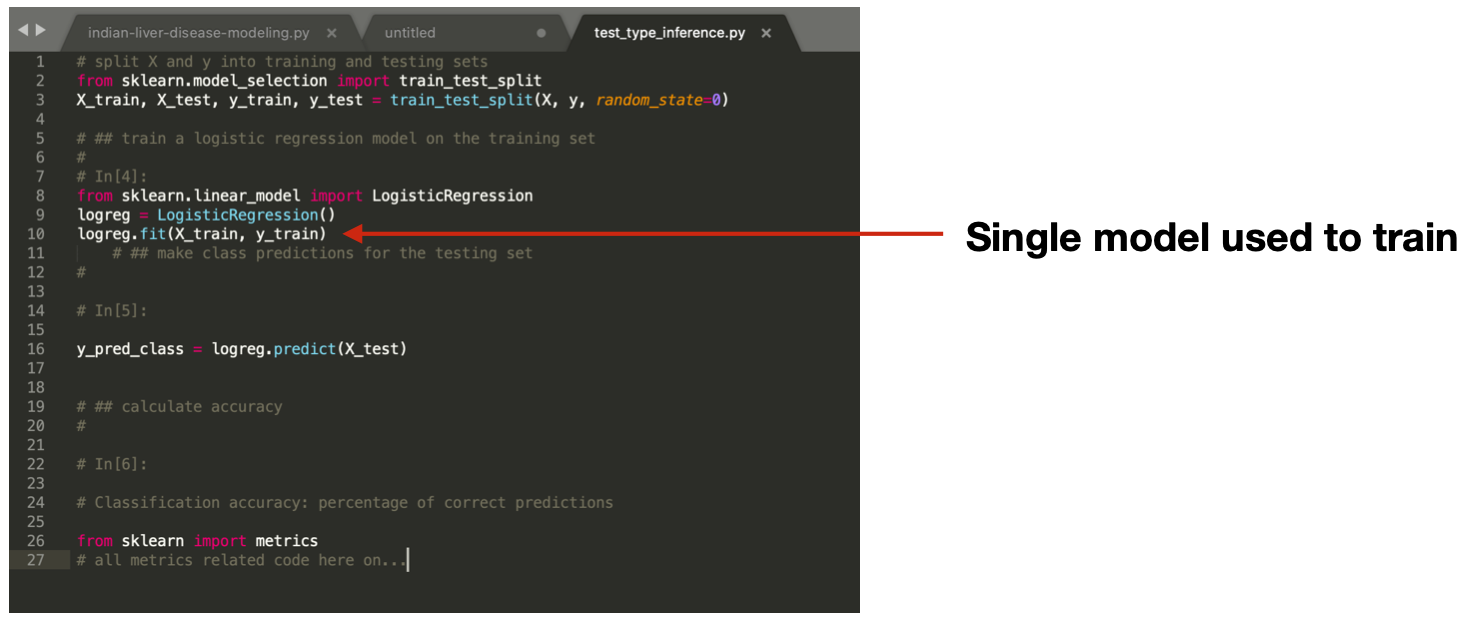
- Check that users developing data science code create multiple models on the same dataset, since machine learning algorithms vary greatly in terms of performance on different datasets (see query here). Here is an example result from the query. As shown in the example, only one model is used to train ona given dataset.
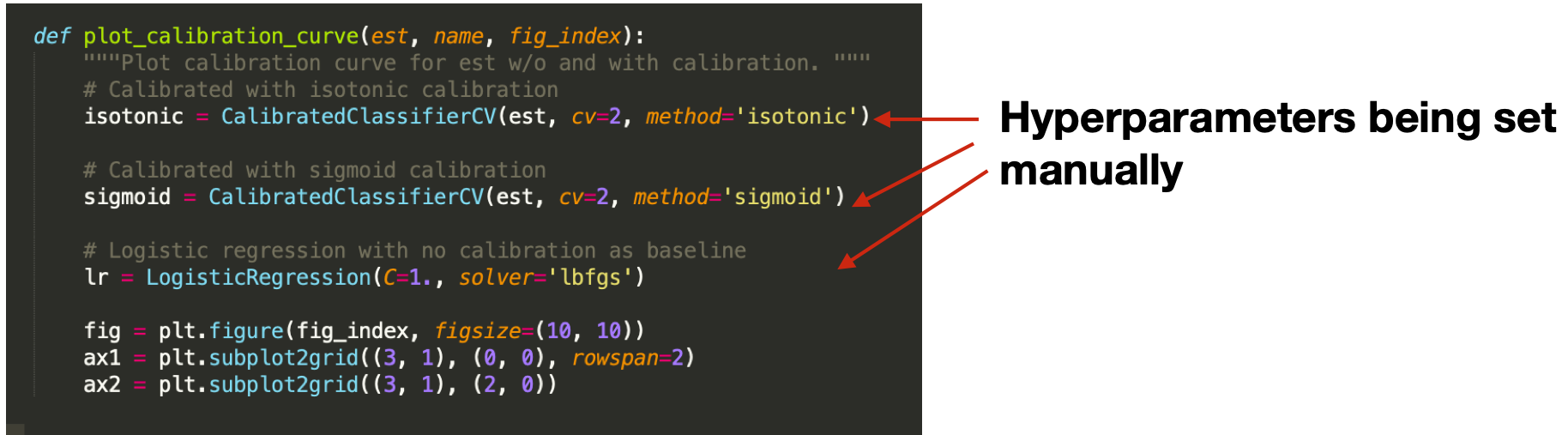
- Check that the users use some sort of libraries for hyper-parameter optimization when building their models (see query here). Here is an example result from the query - the analysis found all three examples of manual sets to hyperparameters.
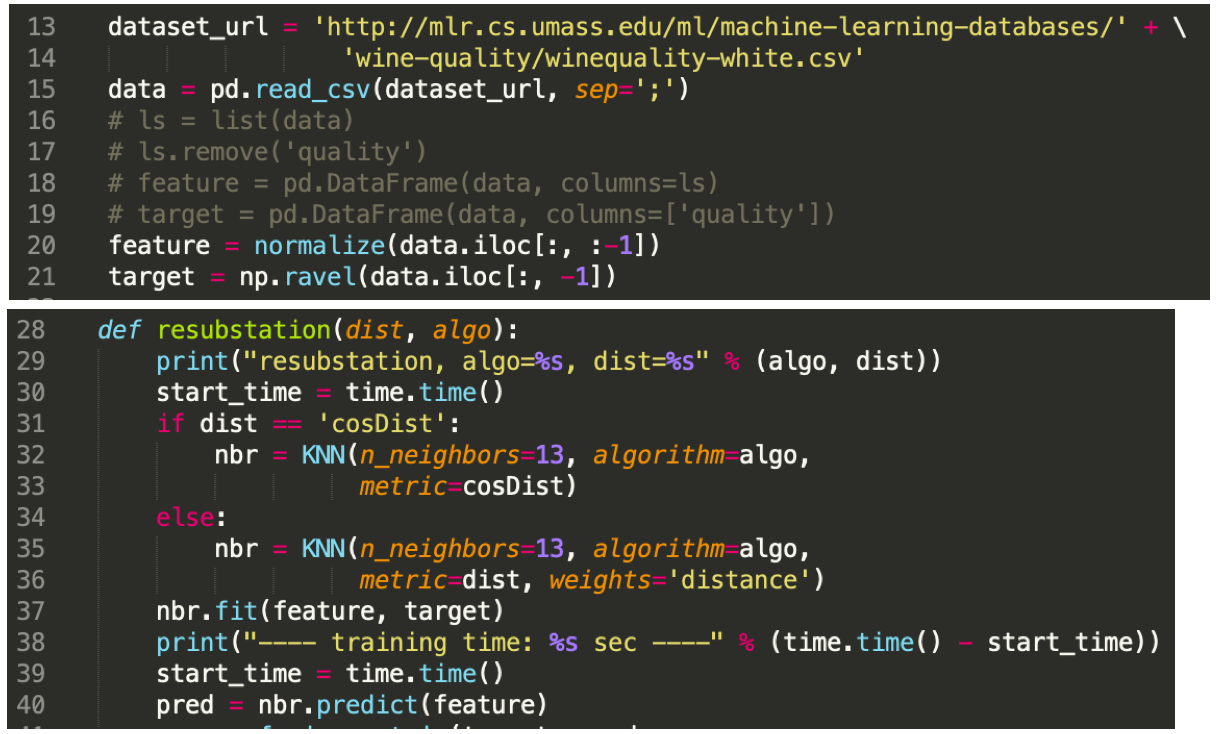
- Check that users developing data science code create the model with a different dataset than the ones they use to validate the model (see query here).
Debugging with Stackoverflow
A common use of sites such as StackOverflow is to search for posts related to an issue with a developer’s code, often a crash.
In this use case, we show an example of searching StackOverflow using the code context in the following figure, based on the highlighted code locations found with dataflow to the {\tt fit} call.
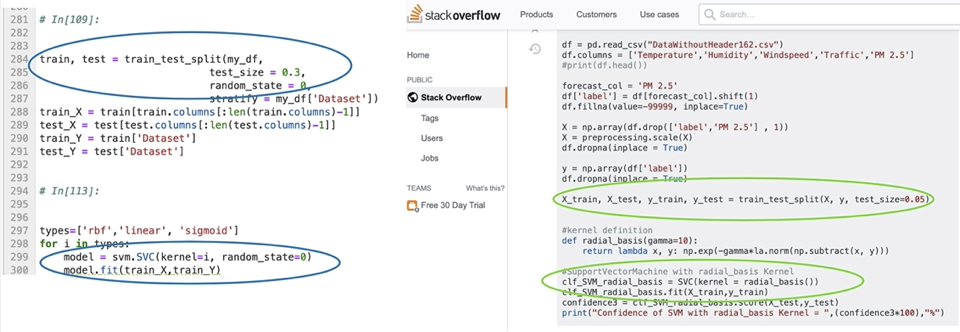
Such a search on Graph4Code does produce the StackOverflow result shown above based on links with the coding context, specifically the train_test_split and SVC.fit call as one might expect. Suppose we had given SVC a very large dataset, and the fit call had memory issues; we could augment the query to look for posts that mention `memory issue’, in addition to taking the code context shown in the above figure into consideration. The figure below shows the first result returned by such a query over the knowledge graph. As shown in the figure, this hit is ranked highest because it matches both the code context in motivating figure highlighted with green ellipses, and the terms “memory issue” in the text. What is interesting is that, despite its irrelevant title, the answer is actually a valid one for the problem.
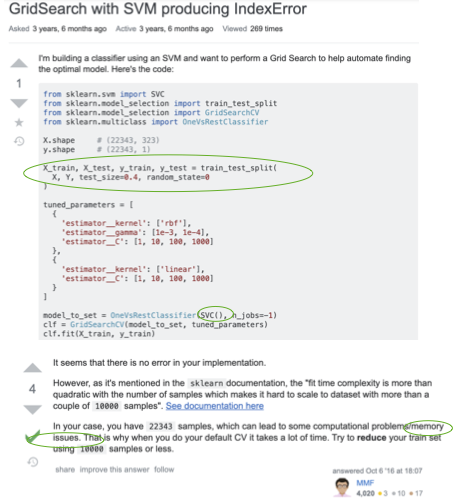
A text search on StackOverflow with sklearn, SVC and memory issues as terms does not return this answer in the top 10 results. We show below the second result, which is the first result returned by a text search on StackOverflow. Note that our system ranks this lower because the coding context does not match the result as closely.

Learning from big code
There has been an explosion of work on mining large open domain repositories for a wide variety of tasks (see here). We sketch a couple of examples for how Graph4Code can be used in this context.
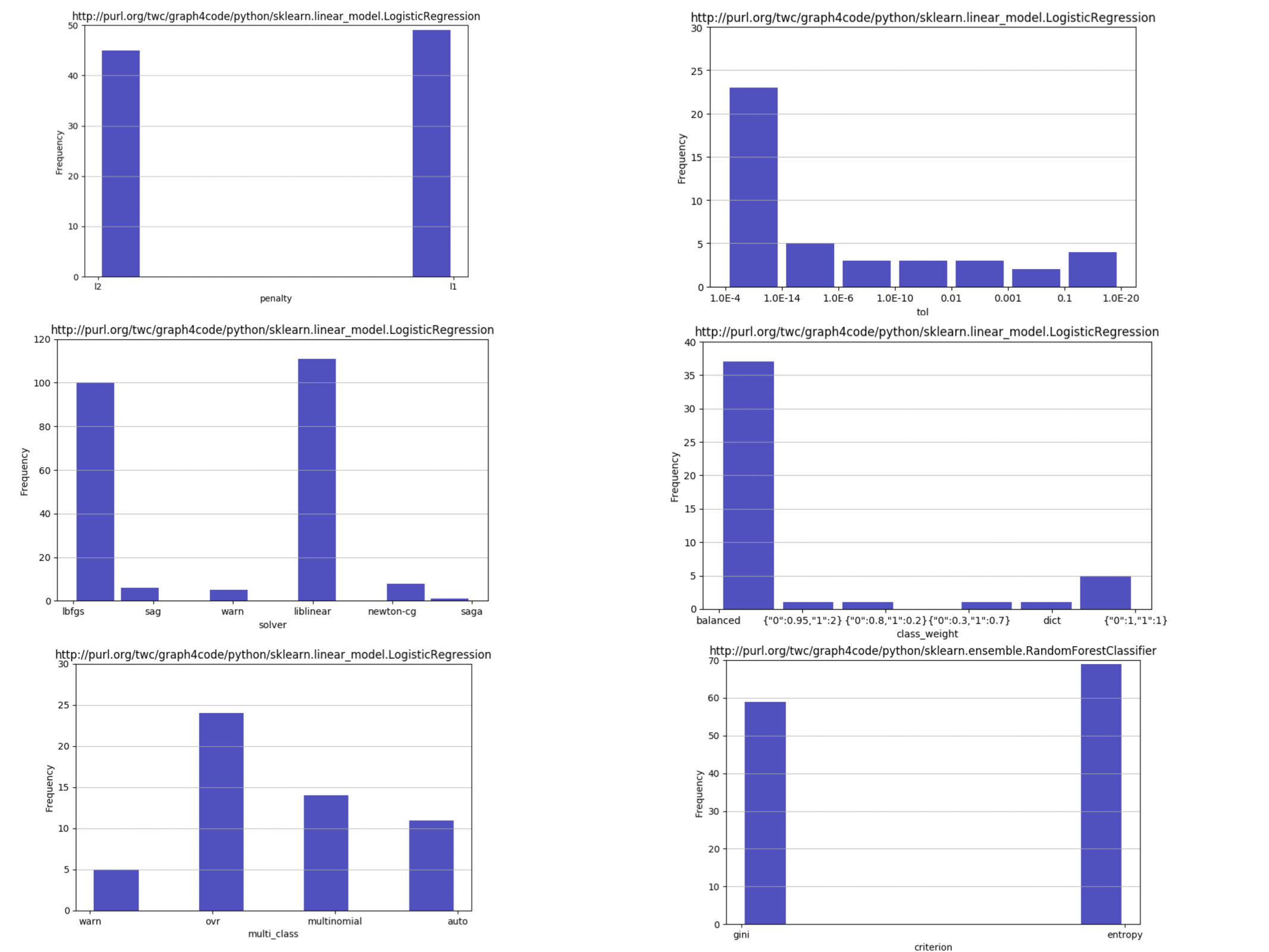
- As an example, again, from a data science use case, the arguments flowing into constructors of models govern the behavior of a model to a large extent. These so-called hyperparameters are often optimized by some sort of search technique over the space of parameters. Hyperparameter optimization can be seeded with the appropriate values using query here to restrict search, using any of the standard hyper parameter optimization packages (see query here).
- The graphs themselves can be used to perform automated code generation by using them as training sets. As an example, Code2seq is a system that generates natural language statements about code (e.g. predicting Java method names) or code captioning (summarizing code snippets). Code2seq is based on an AST representation of code. Graph4Code can be used to generate richer representations which may be better suited to generate code captioning.